


DeepSeek's r1 Breakthrough
Thanks to Chinese AI lab DeepSeek, AI costs are plummeting, reasoning AI will be democratized, and more of the tech stack is investable for AI themes.

Chinese AI lab DeepSeek released r1 and shocked the market that a smaller, relatively resource constrained AI lab could cost-effectively match OpenAI.
DeepSeek probably did train on OpenAI’s data, but their technical work is a real breakthrough that unlocked reproducible, cost-effective advanced reasoning AI.
I’m excited. I think the >95% drop in reasoning AI cost makes far more of the tech stack investable for AI themes and could be huge for locally-run AI.
DeepSeek’s r1 might be the first time I’ve seen something as in-demand as AI suddenly drop in price by >95% overnight, and I think it’s great. I’ve consistently held that inference will be the largest long-term driver of AI infrastructure demand since AI use-cases will be abundant.
I was surprised to see the market react so negatively to the news on Monday, especially because I had been talking with both technical and market-focused people about DeepSeeks advances for weeks. I thought its progress was much more broadly and well understood, so this week was a wake-up call that I’ve been living in a bubble. Personally, I took the opportunity on Monday to add to my long positions in the AI supply chain since what DeepSeek achieved is completely aligned with my expectations - it just happened faster than I had expected.
Unexpected change is scary. Thankfully, I think my readers were likely better prepared than most for what happened this week. Here’s a quick recap of why:
In Human After All, I analyzed OpenAI’s o3 model relative to the cost of human intelligence and the history of cloud economies of scale.
In After Training your AI, Give it Time to Think, I analyzed test-time compute strategies used by models like OpenAI’s o1, o3 and DeepSeek’s r1, which uses exponentially more compute to deliver linearly better results.
In Electric Feel and Feeding Colossus, I analyzed the energy demands of AI infrastructure with a focus on the big builds by Meta and xAI.
Before going into more depth about the economics, strategy, and market dynamics of DeepSeek’s work I want to make mention of something really important: the reinforcement learning strategy employed by DeepSeek is most effective for math and programming use-cases since that content is easily verifiable. For example, if during reinforcement learning (RL) the model-in-training spends 5 minutes attempting to compute 2+2 and erroneously concludes this equals 7.8234, it’s easy to verify the conclusion was incorrect and to tell the model to go back and try again (and again, and again, and again…).
I think DeepSeek’s reinforcement learning approach provides a great framework to quickly and vastly scale up reasoning AI in domains where ground truths can be confirmed programmatically. I think it’s going to be much tougher for DeepSeek or any AI vendor to repeat this trick in domains with more subjective output without vast quantities of human-generated training data.
What’s in Fred’s Rotation Today
AI Infrastructure Demand Should Remain On Track
I’m excited that the cost of intelligence just decreased 90%+, and that o1 class models can now be run locally. I can understand why the market would panic to understand what such a big change in economics means for the various parts of the AI value chain, but some of the hot takes I’ve seen are excessive.
I believe AI compute demand will continue to increase exponentially even as training and inference techniques become cheaper. Perhaps we won’t see as many companies making plans for $1bn+ AI model training budgets, but all the infrastructure being built is still going to be needed for the tremendous inference demand that I think is coming down the pipe.
I’ve included three charts below regarding the increase in thinking (and therefore compute) performed by OpenAI’s o1 and o3 models and DeepSeek’s r1-lite-preview models to refresh memories and describe why I’m not concerned about an imminent collapse in AI compute demand.
Long-thinking AI models are built to use test-time compute strategies that are producing exponentially more tokens per query than prior generations of models. That is, each time a user asks these smarter models to do something, the models sit around thinking to themselves a lot longer before producing a final answer.
If AI inference compute costs drop 97%, but the quantity of thought tokens consumed per task under this new regime increases 1,000x - 10,000x+, I think it’s safe to bet that demand for compute infrastructure is going to increase by several orders of magnitude! If anything, I think DeepSeek’s cost reduction could make it feasible for more people to take advantage of the smartest and longest thinking AI.
Additionally, if you want to get results from long-thinking AI faster, you’re going to want infrastructure that can run inference as quickly as possible. Today that means you’re still working with GPUs. Perhaps in the near-future this will be inference-optimized ASICs.
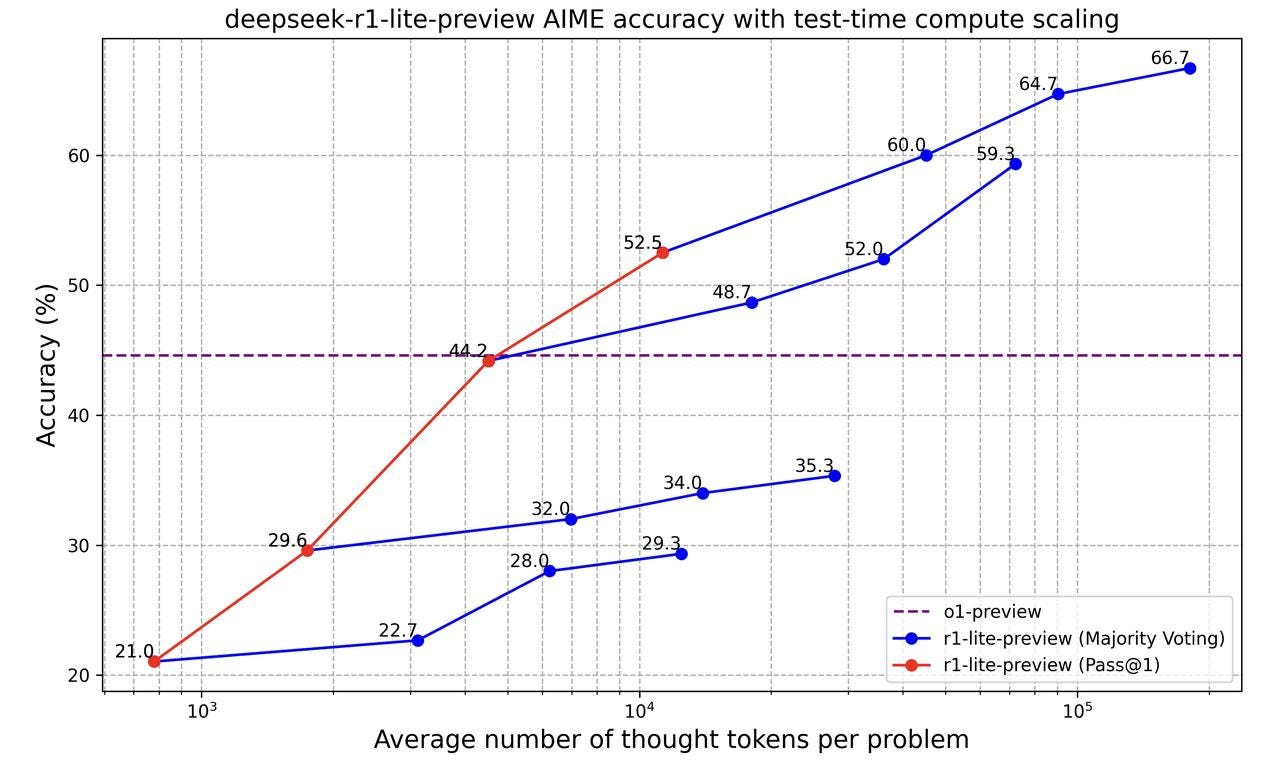
 on the x-axis. The dots indicate increasing accuracy with more compute time.")

Could DeepSeek Really have Done This on their Own?
I mean, yeah. But how much people like my answer probably also depends upon whether they think training on data generated by an existing and powerful reasoning AI counts as “doing it on your own.”
I don’t see any rational reason to disbelieve that DeepSeek in fact built their v3 or r1 models on lower-end GPUs or smaller clusters of hardware. The technical details on DeepSeek’s training approaches were publicly published and their results are successfully being replicated.
For example, researchers at Berkley reproduced DeepSeek’s published approach this past weekend, and the HuggingFace team have been working on open-r1 to reproduce all of the r1 pipeline. I believe results from these projects empirically confirm that DeepSeek’s approach actually can cheaply train LLMs on how to reason.
I think those flat-out denying that DeepSeek could have achieved its results without secret access to massive quantities of H100 GPUs are either too invested into a narrative they’re trying to control about AI development costs, or they’re woefully disconnected from the technical details published by DeepSeek.
I am a believer that DeepSeek has used outputs from competitor models, but I don’t think that diminishes their achievements. I also believe that training models to reason without the output of existing reasoning models would not be nearly as cheap.
I don’t think it matters at this point what DeepSeek did or didn’t do, or where it got its data. The fact is, now anyone with enough capital (but less than last before!) can reproduce their results, and anyone can use reasoning output from DeepSeek r1 to create more reasoning models. We’re past the point where OpenAI or a handful of US AI labs have an oligopoly on reasoning.
New Economics
When I left the sell-side, two of the biggest questions in the market were:
Would the high costs of generative AI decimate SaaS gross margins?
Would useful AI be a cloud service, or could it be run locally?
I think DeepSeek just provided answers to both questions. If reasoning AI can now be consumed at a fraction of the cost of OpenAI’s models and deployed at either the edge or on-device, then it’s much easier to see how software and device vendors can profitably monetize AI. For example, team at unsloth showed how to selectively quantize the larger DeepSeek r1 model and successful run this on 2x H100 GPUs for fast inference, or consumer grade infrastructure for slower but still working inference. This is great!
This kind of improvement in unit economics per task is going to make the AI theme investable in more market segments. I think bulls can start confidently talking about a future where cost-effective AI can add more value within all layers of software, while the bear case about AI causing SaaS gross margin destruction is going to be harder to make. I believe this makes more of the AI theme reasonably investable in the software layer.
I also think this opens up some new opportunities for Mac owners to do some very cool work locally considering its integrated memory architecture and the effectiveness of distilling reasoning into smaller models. Apple itself could benefit substantially from this theme since it builds consumer-ready hardware that can run these AI models, as long as it remembers how to build amazing software products. I had to turn off Apple Intelligence this week since it broke spell correct and caused far more problems than low-resolution and uninteresting Genmojis were worth.
Does OpenAI, or Any AI Lab Have an Advantage?
I think it’s very funny that OpenAI and its supporters are fuming about DeepSeek allegedly training on output from OpenAI’s models. I mean, OpenAI’s core advantage (aside from limitless capital) is its data, which OpenAI scraped and utilized without permission. Just ask the New York Times whether it consented to having its data used by OpenAI - I’m pretty confident the answer would be no.
Considering the drama this week, the leaked Google memo “We Have No Moat, and Neither Does OpenAI” from May 2023 is highly relevant today and provides a prescient view of how the foundational AI market is likely to play out. Google’s team realized there are very few if any competitive moats in the foundational model market, and that the performance gaps between models can close in a moment.
I do not believe AI has suddenly become less valuable in application. I do however think the ability to use existing AI models to bootstrap the training of new models, and the drastic reduction in resources required to run AI models means that we’re moving rapidly towards a democratized future of AI. Without massive federal intervention, which I expect OpenAI is advocating for, I don’t see a way for AI labs to protect their models forever. Eventually, with enough input/output data from consumer-facing AI models, I would think all models could be reproduced.
I think this is going to open up a new field of model security, perhaps beginning with a naive approach offering security through obscurity. Maybe some smart engineers will try to inject incorrect chains of thought in future AI output to poison the logic of anyone attempting to train on their models output? However, that would introduce some new problems as clients of AI companies will want auditable traces of AI models’ thinking - quite the conundrum for anyone trying to simultaneously commercialize and protect their AI.
What’s Up in Singapore?
Did DeepSeek train on a secret CCP-funded supercluster of NVIDIA H100 GPUs? I have no idea, but I would refer you back to the reproduction experiments I cited above to understand that DeepSeek probably didn’t need that scale of infrastructure for its r1 breakthrough.
This news cycle did however get me to focus on the quantity of Nvidia revenue that’s flowing through China, Singapore, and Taiwan. I read Nvidia’s disclosures around geographic revenue and this immediately stood out to me: “Revenue by geographic area is based upon the billing location of the customer. The end customer and shipping location may be different from our customer’s billing location. For example, most shipments associated with Singapore revenue were to locations other than Singapore and shipments to Singapore were insignificant.”

So where are all these Singapore-destined GPUs going? If Nvidia’s geographic revenue reporting is based upon billing location, it’s tougher to tell since many global firms will run their APAC segment out of Singapore. Would I be surprised if these GPUs are remaining in APAC and perhaps ending up in China? No - I wouldn’t be surprised at all.