


After Training your AI, Give it Time to Think
What if AI training performance improvements slam into a wall? Other scaling routes can sustain exponential infrastructure demand growth.

LLM performance has stubbornly converged near GPT-4+ levels, suggesting a performance plateau when scaling compute and data during AI pre-training.
Recent reports suggest frontier labs are struggling to scale their way through a performance ceiling even as training budgets increase 4x - 5x per year.
“Long-thinking” AI offers another leg of exponential scaling, requiring 5x - 10x more infrastructure for inference (positive for semis, energy, data centers).
A friend once told me that the human mind cannot comprehend exponential growth. I’m really not sure that’s the case, and I think he was pitching me on crypto. In retrospect, I probably should have listened more closely.
As an AI optimist and former financial analyst covering cloud software, I love the intoxicating feeling of data that lets you extrapolate big changes from a small set of data. I also love to de-risk my exponential optimism with a sober look at the technical developments driving market dynamics.
The past decade of AI/ML development will likely be described as the Era of Scaling, a period of time when exponentially more resources were thrown at AI pre-and-post training in exchange for predictably positive returns on investment.
However, this era of exponentially scaling the methods used to build GPT-3, GPT-4, LLaMa, Claude, Grok, etc. may be concluding. Recent press reports (e.g. reuters, The Information, etc.), along with commentary from prominent VC’s, suggest that results from scaling up pre-training budgets have plateaued.
While growth in AI model training budgets could slow (a trend that I’m not yet convinced is playing out), there are several other avenues for scaling that I believe would extend the exponential trajectory of AI compute demand.
“The biggest lesson that can be read from 70 years of AI research is that general methods that leverage computation are ultimately the most effective, and by a large margin.”
- Richard Sutton, The Bitter Lesson
AI Model Scaling Went Parabolic
Scaling laws are like the Moore’s Law of deep learning - though Moore’s Law looks absolutely sluggish in comparison with the parabolic growth in compute budgets for AI models over the past decade and a half.
Between 2010 and May 2024, compute budgets used to build frontier deep learning models grew at an average rate of 4x to 5x per year according to research by Epoch AI. For example, within a dozen years (between 2012 and 2024), Google’s compute budget for its frontier AI models increased by ~8 orders of magnitude: a 100,000,000x increase in FLOPs invested for their leading AI models.

Epoch AI’s orderly log-axis chart hides the exponential reality behind growth in AI model training budgets. For the sake of illustrating a good story, I asked my AI assistant to plot this training budget data on a typical linear Y axis. In this view, the growth in compute used to train advanced deep learning models over the past 14 years would look a bit more like this:

For fun let’s also compare this chart to Nvidia’s data center revenue over the past 16 quarters:

While the timelines here don’t map 1:1 and I am not projecting out Nvidia’s revenue, I think this gives us a fun, illustrative comparison of where exponentials appear across deep tech and financial markets - particularly as the global AI arms race rages on.
AI Scaling Laws: The Moore’s Law of AI
The fundamental scaling laws of AI have historically predicted that model loss (synonymous with model performance) improves with increases in three training budget categories:
Compute power: Performance scales as a power-law with the amount of compute used for training, with exponentially more compute generally yielding linearly better results
Model parameters: Performance improves predictably with exponential growth in model parameters, also following a power-law curve
Training data: Increasing dataset size leads to performance improvements, with Chinchilla scaling describing the strongest modern understanding of this tradeoff
Scaling laws have been highly useful for both AI labs and industry observers as they provide a way to calculate AI training ROI, and to predict how to pull levers (e.g. compute, parameters, data) to reach performance targets.
For example, the Chinchilla scaling law predicts that model training should run with a roughly 20:1 ratio of training data tokens to parameters. The authors of the Chinchilla scaling paper succinctly framed this law as:
“…for every doubling of model size the number of training tokens should also be doubled.”.
From my financial analyst perspective, Chinchilla scaling helps me do useful things like estimate that AI labs are near the limit of their ability to scale with public internet data. Data sets such as RedPajama v2 contain ~30 trillion tokens, enough for a ~1.5 trillion parameter model (3.75x the size of LLaMa 3 400bn) according to Chinchilla scaling.
If AI labs continue to try to expand their models' 10x parameter counts every ~2 years, the utility of scaling parameter counts on public internet data following Chinchlla scaling may be exhausted with this next scaling cycle.
Pre-training scaling laws also provide a number of attractive features for the financially minded:
AI labs can determine the optimal allocation between model size and training data for a fixed compute budget
Scaling laws allow labs to estimate ROI for different model scaling approaches, balancing training costs against expected performance gains
Hardware infrastructure investments can be planned years in advance following the predictions of scaling laws
AI architectural choices can be tested on smaller scales and extrapolated with scaling laws, de-risking expensive large-scale training
Scaling laws help to identify potential data bottlenecks - for example, a 100T parameter model would require ~180 petabytes of text data
Scaling laws inform decisions about data collection and curation strategies
A Pre-Training Plateau is Not a Hard Ceiling on AI Infrastructure Demand Growth
Despite the press about AI training plateaus, I am not worried about an imminent collapse in demand for AI resources. I believe we are still very early stages in what will be decade-long doubling (Source: trust me, bro) of the global IT infrastructure footprint.
While I’m waiting for more proof points of successful LLM-powered applications (beyond ChatGPT, Claude, Perplexity, Azure AI Services, Glean, …, etc.) I believe that long-thinking AI powered by test-time scaling strategies will be an incremental driver of exponential AI demand growth.
Test-time scaling in general extends inference to extract better performance from existing models without necessarily retraining or increasing model size (with more special sauce likely added behind the scenes).
OpenAI’s o1 model introduced this architecture to consumers with its extensive chain-of-thought reasoning and behind the scenes work to “think” about a problem and develop a solution by using exponentially more inference-time compute.
This week, Chinese AI startup DeepSeek released deepseek-r1, which incorporates test-time scaling strategy to beat the performance of OpenAI’s o1-preview model.
DeepSeek also introduced a new “Inference Scaling Law” with its r1-lite release, which shows a roughly linear increase in model accuracy by applying exponentially more compute during inference.
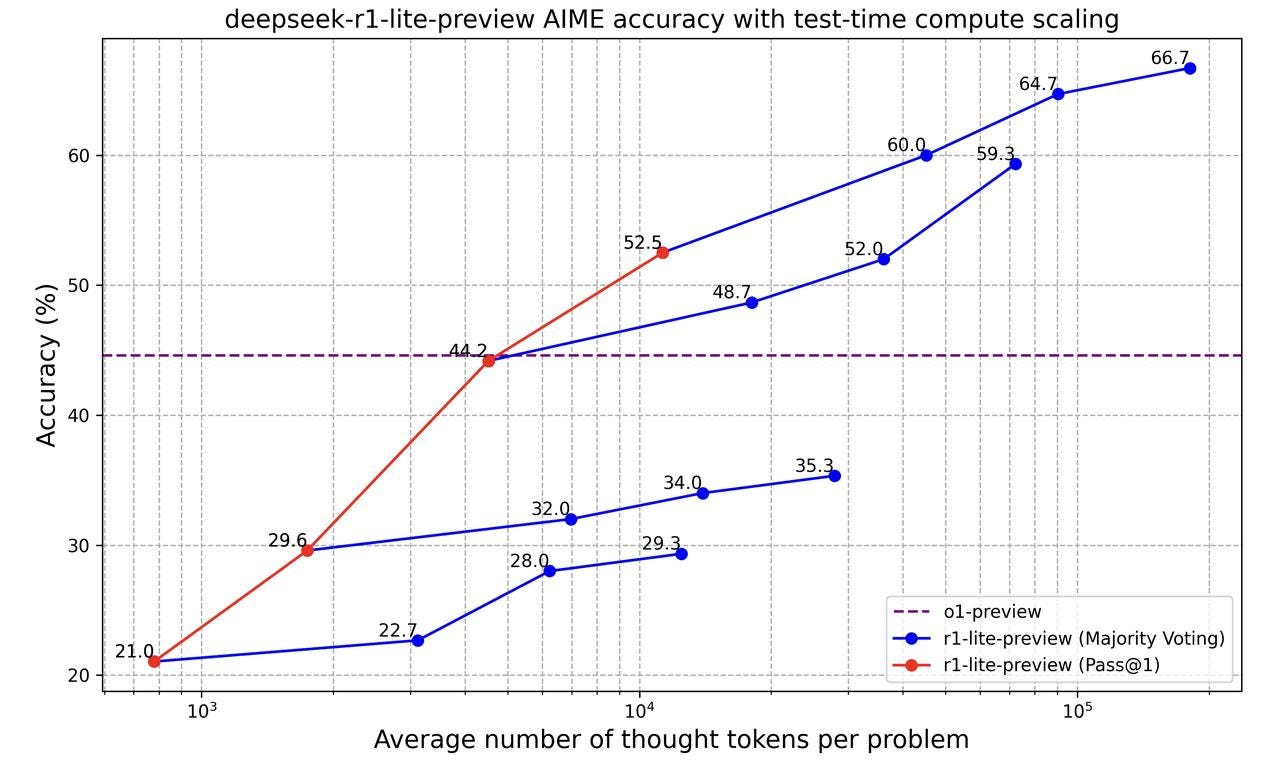
I believe we are witnessing the start of another S curve in the AI space - one where longer thinking AI fills demand slack left by a resource re-allocation cycle that could result from a plateau in pre-train scaling.

Long-thinking AI could require an infrastructure buildout that rivals the strategic GPU clusters built to train the largest AI models.
Long-Thinking AI is an Infrastructure Hog
If long-thinking AI becomes ubiquitous, AI applications will need exponentially more infrastructure for inference workloads. Even if some of the incremental infrastructure demand could be offset by improvements in hardware (e.g. Nvidia’s Blackwell platform), exponential growth in thinking time would require exponentially more compute capacity without a hardware or algorithmic breakthrough.
I typically look to Nvidia’s published MLperf benchmarks to assess machine capacity and throughput data, but in this case Nvidia’s CFO Colette Kress made a particularly helpful comment during the company’s Q1 2025 earnings call:
"For example, using Llama 3 with 700 billion parameters, a single NVIDIA HGX H200 server can deliver 24,000 tokens per second, supporting more than 2,400 users at the same time."
We are going to use this commentary and make a few assumptions:
o1-preview and deepseek-r1-lite-preview performance is achieved with a 5x - 10x increase in tokens consumed during long thinking tasks
Long-thinking models are presently capped at a ~100x increase in tokens consumed during long thinking tasks due to context window limitations.
If an HGX H200 server can serve 2.4k LLaMa 3 users simultaneously, I believe it’s reasonable to estimate that switching to long-thinking AI inference that consumes 5x - 10x as many tokens per response would correspondingly reduce users served by this HGX H200 box to 240 - 480. If long-thinking is scaled up to 100x tokens vs. base inference, perhaps just 24 users could be served simultaneously by this ~$300k+ beast of a box.
Assuming that 50% of ChatGPT’s reported ~200mn weekly active users are also daily active users (reasonably conservative considering Facebook reported a consistent 66% - 69% DAU/MAU ratio), and assuming that users access ChatGPT evenly throughout the day, this would imply ChatGPT could have ~4mn simultaneous users. Considering Colette’s commentary about HGX H200 throughput, serving ~4mn simultaneous users with a GPT-4 scale model might require ~1.7k HGX H200’s (or ~14k H200 GPUs).
If long-thinking AI is rolled out to these same 4mn users, the required resources could expand massively to 8.5k - 17k H200’s HGX H200’s (or 68k - 136k H200 GPUs) depending upon how long the AI model is allowed to think.
The scale of compute potentially needed to power a long-thinking AI workload serving 4mn simultaneous users would be comparable to xAI's famous Colossus GPU cluster, which is used to train xAI’s Grok family of large language models.
I’m excited about a future where AI inference clusters rival the largest training clusters in existence today.
